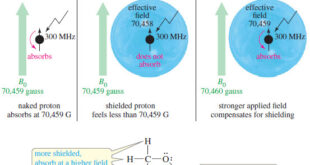
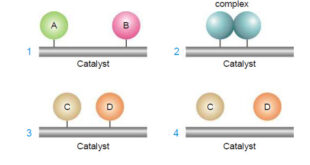
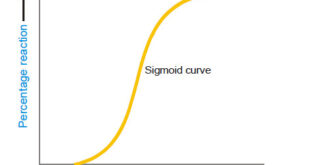
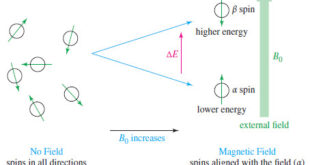
Read Chemistry
Read Chemistry
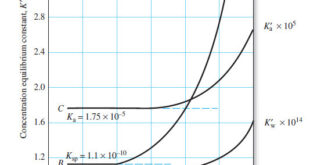
The Effect of Electrolyte on Chemical Equilibria – Experimentally, we find that the position of most solution equilibria depends on the electrolyte concentration of the medium, even when the added electrolyte contains no ion in common with those participating in the equilibrium. – For example, consider again the oxidation of …
Read More »The Effect of Electrolyte on Chemical Equilibria